Computers:
Page 3 of 11 •  1, 2, 3, 4 ... 9, 10, 11
1, 2, 3, 4 ... 9, 10, 11 ![]()
Your login can be stolen even if you did not check "remember me"!!
![]() Shelby Fri Aug 20, 2010 4:58 am
Shelby Fri Aug 20, 2010 4:58 am
Let's hope all the browser vendors will fix my bug report, as every website is affected on the entire internet. :eek:
The risk is low. Only if you have a virus on your computer and don't know it.
Prior discussion:
http://www.ietf.org/mail-archive/web/hybi/current/msg03359.html
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -

Re: Computers:
![]() skylick Fri Aug 20, 2010 8:15 am
skylick Fri Aug 20, 2010 8:15 am
i encounter on the internet.
skylick- Posts : 54
Join date : 2008-11-19
Browser is much more insecure than you think
![]() Shelby Sat Aug 21, 2010 2:02 pm
Shelby Sat Aug 21, 2010 2:02 pm
https://bugzilla.mozilla.org/show_bug.cgi?id=588704#c36
It might help if more people voted for this bug.
This applies to all browsers, not just Firefox.
I raise this not only as a practical security hole, but also because it has massive domino effects on internet economics. Please read the bottom of comment #14.
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
Secure Websites Are All a Lie
![]() Shelby Sun Aug 22, 2010 7:08 am
Shelby Sun Aug 22, 2010 7:08 am
Do NOT trust any website to guard your private data, not even banking websites are secure. I will explain why and how you can help to make sure it gets fixed immediately! I mean that every website where you enter a password to get access, is not secure, no matter what that website says to the contrary.
You may read all the technical details at the following bug report I filed for the Firefox browser:
https://bugzilla.mozilla.org/show_bug.cgi?id=588704#c36
Note as far as I know, this web security problem applies to all browser software, including Internet Explorer, Google Chrome, Safari, Opera, etc..
Two critical vulnerabilities exist on every browser software that you use to surf the web, and even if your browser says the website is secure (small lock icon at bottom), it is a lie and here is why:
1) Hacker in the network can intercept and proxy the secure connection between your browser and the server of the secure website, and thus steal (and even alter) the data that is transferred back and forth. It is impossible for your browser and the website server to know the hacker is in the middle. This hacker could even be the government, because nearly all traffic on the internet passes through government routers (this was verified anonymously by someone who works as a programmer inside Homeland security), and if government can end your security, they can also end your ability to have free speech:
http://en.wikipedia.org/w/index.php?title=Carnivore_%28software%29&oldid=376444660
http://news.cnet.com/8301-13578_3-10463665-38.html
http://www.prisonplanet.com/obamas-war-on-the-internet.html
http://www.prisonplanet.com/google-plans-to-kill-web-in-internet-takeover-agenda.html
2) Hacker can get a virus into your computer (even if for just a few minutes), and that virus can access your secure connection (even if you have your own SSL certificate and/or hardware password generator device and/or biometric device), because the connection encryption password (and/or the site session authentication keys) are not encrypted properly by the browser.
I am not joking nor exaggerating, and I am sufficiently expert on this. Read the Firefox bug report to check my expertise. If you ask another security expert for an opinion, make sure they read the technical details first, because most so called "experts" are not fully aware of the logic that applies.
Neither of these threats have anything to do with hacking the server of the website. The first threat is called a "man-in-the-middle attack" and it has nothing to do with a virus in your computer, and it applies to everyone who is using the internet, except for those very few of you who have installed your own personal SSL certificate on your browser software. However, even if you did install your own personal SSL certificate, the second threat applies to everyone. The second threat occurs when a virus can sneak past your firewall and anti-virus software, and then it can steal the data that keeps your connection secure, because that data is not encrypted properly as it should be. And note that the type of encryption that must be used to fix this problem, is very specific and requires the use of one-way hashes.
There is an easy way we can fix the second threat. Browsers must properly encrypt the data they store that controls the security of the (connection and login session authentication) for the website (see my Firefox bug report for the details), so that the virus can not use that data even if it accesses it. In the Firefox bug report, I explained how this encryption can be done in such a way that it is secure. In that same bug report, I also suggested a way that the browser software could automate the issuance of personal SSL certificates in order to fix the first threat.
If you care about this current (and looming to be critical) security and free speech threat, you need to click to that bug report I filed for the Firefox browser, and then click the "Vote" link near the top of that bug report page and to the right of the "Importance" choice. You must first sign up for free to the bugzilla.mozilla.com site, before you click the "Vote" link. You don't need to be a technical expert to sign up and vote. Any one is allowed to sign up and vote. It is your right as member of the internet community which uses Firefox. If we can get Firefox to fix the problem, then the other internet browsers will also, because they don't want Firefox to have an advantage. Website programmers want to make their sites secure, but we need the browsers to fix their side of the problem first.
Do not expect this problem to get fixed if you all do not hammer Firefox with sufficient (as in hundreds of) votes. Firefox has had a similar bug report on this problem since 1999, which they have not fixed after 11 years:
https://bugzilla.mozilla.org/show_bug.cgi?id=588704#c27
Here is your chance to fight for our free speech rights. All you have to do is click and vote. By protecting our ability to communicate securely on the internet, you will have insured that we can always talk freely to each other without government tracking. And you will have thwarted hackers current ability to steal your bank account and other important sites where you normally login (sign on) with your password.
I urge you not to dismiss this matter, and if you agree about the importance, please act immediately as I have suggested.
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
re: Secure Websites Are All a Lie
![]() Shelby Sun Aug 22, 2010 8:04 am
Shelby Sun Aug 22, 2010 8:04 am
https://goldwetrust.forumotion.com/technology-f8/computers-t112-45.htm#3470
Note I also sent this to some high traffic financial websites for publishing. If you have the ability to publish this some where, I urge you to do so, and you have my permission to do so.
The reason this is critical, is explained at the link above. I will elaborate below.
1) This security hole is critical because secure websites are the only means the public has to guard their ability to use the internet for private data, without being threatened or coerced. If global chaos were to occur, then secure websites will be one of the important ways that the global economy can isolate itself from the cancer causing the chaos.
2) We do not have much time before global financial chaos due to systemic debt ratios (in most major western countries) which are beyond all historic episodes of hyper-inflation. Those of us like myself who have studied the math since 2006, are acutely aware that the end game is inevitable and intractable.
3) I have done some and welcome more expert peer review of my technical allegations. We don't have time to get mired in the politics of a security working group on this matter. I am 99.9% sure that I am correct on the technical allegations. I am sure there is no workaround without the proper encryption fix in the browsers, and that all so called "secure" websites are insecure as I have alleged and described. I am trying to get the word out to the public quickly in order to accelerate the process. Let any additional peer review come as it will once there is some push from the concerned public. Not promoting this critical problem, might cause it to be ignored by many security experts who have their heads buried deep in other matters.
4) The reason I am sure of the technical accuracy of my allegations, is because for one thing I have much expertise in website security:
https://bugzilla.mozilla.org/show_bug.cgi?id=588704#c13
(read the bottom of this comment for my credentials)
Also because no security expert that I have discussed this with so far, has been able to refute my allegations. Expert feedback to me has been that one should not use cookies for secure websites, and that one MUST use an SSL certificate in the browser AND in the server to prevent
man-in-middle-attacks. The "secure" websites we access are using SSL certificates, but none (very few) of us are using SSL certificates in our browsers. So that is the threat #1 I wrote about. No browser or "secure" website warns you about this threat #1. Instead they pretend they are secure (with the small lock icon you see, which is a lie). Additionally, no expert has refuted my allegation, that even if we don't use cookie and we use an SSL certificate in the browser, that it doesn't stop a virus on our computer from reading the SSL encryption private key and/or the session login id (even if it is in memory instead of on disk in a cookie). This is because the browser is not encrypting the SSL encryption private key nor the session login id, when it stores/holds them on disk and/or in memory on your computer. This is the threat #2 I wrote about. No browser or "secure" website warns you about this threat #2. Instead they pretend they are secure (with the small lock icon you see, which is a lie).
The reason these threats may not have been exploited in large scale so far, is probably because there are so many other easier ways to attack users' security, such as hacking into the webserver computer itself, CSRF bugs in the website, or phishing the customer password using social engineering. Nevertheless, for those of us who provide well hardened webservers for our sites and who are expert in our anti-CSRF and
anti-phishing tactics, then the threats #1 and #2 that I am alleging are critical to whether our secure websites can be secure when it really matters most in near future. By the time we find out that we need it, it will be too late to fix the problem quickly, if we don't act now.
I urge any one who doubts the technical veracity of my allegations to either post a technical comment to the Firefox bug report I linked, or email me. I welcome peer review.
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
re: Secure Websites Are All a Lie
![]() Shelby Sun Aug 22, 2010 3:55 pm
Shelby Sun Aug 22, 2010 3:55 pm
there is actually already a Zlob virus which proves I am correct:
https://bugzilla.mozilla.org/show_bug.cgi?id=588704#c40
Also I added some more clarifications driven by recent peer review:
https://bugzilla.mozilla.org/show_bug.cgi?id=588704#c41
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
re: Secure Websites Are All a Lie
![]() Shelby Sun Aug 22, 2010 6:43 pm
Shelby Sun Aug 22, 2010 6:43 pm
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
McSh8 vs. Linsucks
![]() Shelby Mon Aug 23, 2010 12:39 am
Shelby Mon Aug 23, 2010 12:39 am
Shelby wrote:I just finished a discussion with an expert. And now I think I understand why this problem has not been fixed and never will be fixed.
The geeks who make the worlds open source software, which includes most internet software, love Linsucks and hate McSh8's Windoze. They want to see Windoze perish in its own insecurity. And McSh8 also wants its Windoze to get many viruses, because it makes people want to upgrade to new and improved versions (and often buy a new computer at same time, so hardware vendors also like more viruses).
The more viruses, the more everyone in the industry profits.
So nobody has an incentive to provide you the customer with something that works properly.
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
Good news!
![]() Shelby Tue Aug 24, 2010 9:44 pm
Shelby Tue Aug 24, 2010 9:44 pm
Shelby wrote:Firefox will try to fix this problem (but I don't know when):
https://bugzilla.mozilla.org/show_bug.cgi?id=588704#c47
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
Why this crap matters to YOU
![]() Shelby Sun Aug 29, 2010 1:02 am
Shelby Sun Aug 29, 2010 1:02 am
Shelby wrote:I think there are far too many cases where we chase the shadows, instead
of real holes and solutions. And this is destroying the
freedom/opportunities on the internet in my opinion (will end up with the
big server farm companies being the only ones whitelisted and rest of us
in slavery).
For example, the whole concept of firewalling everything and then
whitelisting the internet. That isn't security, it is just a way of
letting only the viruses come in and not the useful programs. When
programs have to written with STUN tunneling like a virus, the internet is
fundamentally broken by Almost-Better-Than-Nothing security models. So now
99% of the possible internet connections are unavailable unless one writes
their program like a virus...
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
server farms can't adapt to dynamic change, Re: IETF is trying to kill mesh network
![]() Shelby Sun Aug 29, 2010 11:36 pm
Shelby Sun Aug 29, 2010 11:36 pm
http://forum.bittorrent.org/viewtopic.php?pid=196#p196
I was criticizing bittorrent for socialism design. I think they may have fixed it due to my input?
>> Isn't internet same as a bifurcating tree?
>
>
> Yes, I believe it is.
[snip]
>> > Speaking of which there was some genetic algorithm
>> > program that someone wrote, to distribute bandwidth to
>> > a number of nodes from a centralized location. There was
>> > some cost associated with the capacity of each connection.
>> > Maybe it was delivering electrical power. It turned out a
>> > centralized generator feeding each endpoint on identical
>> > capacity wires was horrendously inefficient. It ended up
>> > evolving into a far more efficient tree like arrangement.
>> > I wish I could remember the source, the associated pictures
>> > were fascinating.
>>
>>
>>
>> Find it!!! I need that to refute those who think the
>> server farm is more efficient!!!!
>
> I found it, you're going to love it.
> It's part of Richard Dawkins' TheBlind Watchmaker".
>
> http://video.google.com/videoplay?docid=6413987104216231786&q=blind+watchmaker&total=117&start=0&num=10&so=0&type=search&plindex=1#
>
> Start around 36:00.
Okay I watched it. But that is already the structure of the internet, so how does that argue against the economics of the centralized server?
Rather I think it is the point at the 34 - 36 min portion that says the more important improvement of many independent actors is that it can anneal to complex dynamics. I say that is the reason centralized anything fails, is because it can not adapt fast, due to limitation of mutations (99% of internet is not able to cross-connect).
And fast adaption (30 generations to solve 350 million possibilities due to a large population of mutations on each generation) is what makes evolution so fast.
What you think?
>> Okay I watched it. But that is already the structure of the internet,
>> so
>> how does that argue against the economics of the centralized server?
>
>
> I guess it doesn't.
>
> One argument against a centralized server is the cost burden. The
> users don't share the burden.
Yes conflation (socialism) is mis-allocation.
>
> If you have an infrastructure that supports sharing of the burden
> across users, the barrier to entry is nil. With the bandwidth skewed
> as it is towards the consumer, not the producer, you need a google
> with dedicated servers to get in the game. It's a recurring theme that
> once a site takes off it is killed by its own success -- server failures,
> inability to serve pages, denial of service... what works for 1000
> users can break horribly for 20,000.
Small things grow faster, because (1856 2nd Law thermo, universe is closed system by definition) nature wants to trend to maximum disorder, so mass can not constantly accumulate exponentially.
>
> The key about fast progress is making it easy to innovate and
> introduce new concepts.
Ditto above and below...
> My network concept is itself just
> infrastructure, on top of which an unlimited number of new
> services could be delivered. The current internet is too subject
> to political whim.
>
> Rather I think it is the point at the 34 - 36 min portion that says the
>> more important improvement of many independent actors is that it can
>> anneal to complex dynamics. I say that is the reason centralized
>> anything
>> fails, is because it can not adapt fast.
>>
>> And fast adaption (30 generations to solve 350 million possibilities due
>> to a large population of mutations on each generation) is what makes
>> evolution so fast.
>>
>> What you think?
>
>
> Evolution is fast because it isn't a random walk. Only steps that are
> along the gradient are kept. The 350 million possibilities represent
> points in some N dimensional space. Distance in this space is always
> very small. If there is a fitness quantity associated with each of the
> 350 million possibilities, it is trivial to zoom in on a local maximum.
You just restated what I wrote above.
The fact that each generative step has millions of candidates, means that the system anneals rapidly. It is a gradient search (Newton's method), but stochastically. The stochastic part is very important, because a single actor gradient search can get stuck in a local minima.
>> Build it and they will use it and the centralized inertia will get overrun by
>> humanity.
The solution is we need to make P2P more popular and mainstream. Then the
govt can never block it any more. Game theory! That is why we have to
build a P2P programming tool and build it into the browser and then let
the web programmers go mad with it. Then the rest is history.
Read this please for popular use cases:
http://www.ietf.org/mail-archive/web/hybi/current/msg03548.html
http://www.ietf.org/mail-archive/web/hybi/current/msg03549.html
http://www.ietf.org/mail-archive/web/hybi/current/msg03231.html
Sure nature due to Coase's Theorem will eventually route around the
centralized inertia, but it is the person who facilitates the rate of change that earns the brownies.
> Anyway the current internet stinks for any sort of virtual
> mesh network. It is heavily skewed on the downstream
> side. I can get 500K bytes/second down easily but it bogs down
> if I'm even uploading 30K bytes/second.
So the initial applications will evolve to that cost structure, but it
doesn't mean the mesh is useless.
and once the mesh is there, it will force the providers to balance out the
bandwidth.
The problem is their current business models will be toasted???
> I believe an ideal
> internet connection would be 2 units upload capacity for
> every 1 unit of download capacity. That would allow any
> node to source data to 2 children. Each of those could
> retransmit the data to 2 more children. This binary tree
> could be extended forever. Any node could be as powerful
> as the most powerful servers in the world today, as the
> receivers of the data expand the data delivery capacity.
The current limit is only bandwidth. Bandwidth isn't the most important
problem. The paradigm shift of just being able to make that structure
with limited bandwidth is huge.
We can upload to 2 connections now.
>
> This choice reflects either the consumer nature of the
> public (most people want to receive data, not source it),
> or an intentional effort to push people into being consumers,
> not producers.
Neither. It is the current design of the WWW. We simply need to change
it and the economics will overrun any one who tries to stop it.
> My network demands symmetric bandwidth
> capacity, equal up and down.
Build it and they will use it and the inertia will get overrun by humanity.
Furthermore, those humans are programmers and can inject code, these have
a life of their own...etc...
> Interesting. How do you get it started programming itself then?
> A machine with infinite computing power magically programs
> itself? How?
>
>
>> It will program itself, that was precisely my point.
> There is a reality out there that is solid and real and it doesn't depend
> on my consciousness or any other for its reality.
>
> I go into the forest near my house. I find on the ground layer upon layer
> of leaves. The ones at the bottom are most decayed, on top they're
> newer, just from last fall. Each leaf had a history. It all was there even
> if I nor anyone else came to look at it. The universe has a history, the
> deeper you dig the more details you uncover. It didn't all just come into
> reality when I or anyone looked for it. The only way for the sheer volume
> of detail to have gotten there was for it to have existed and had its own
> history.
Yes but you didn't know it.
And you will never know it all.
But mesh networking will increase your knowledge capacity by several
orders-of-magnitude.
Sorry for the slow reply, I am programming simultaneously.
below...
>
> I'm limited by my location and my own senses. I didn't perceive your
> sunrise or your cockroach. I perceived on my computer screen words
> that supposedly originated from someone on the other side of the
> planet describing an experience he had moments before. A vast number
> of such experiences are going on right now all over the planet, yet I'm
> not connected to them so I don't perceive them directly. They exist
> independent of my contribution as observer.
Don't argue against virtual reality. You argued for it before. You said
we could tap into brain and it would just as real as reality.
>
> If a tree falls in the forest and there is no one there to hear it, does
> it make a noise? Yes, sound waves are produced. If a human were
> hearing it he'd perceive it as humans do. If a human isn't there there
> is no human perception of it. But the sound waves occur regardless.
> Wind is produced, other trees are rocked around a bit. Animals perceive
> the noise in their own way. It all happens whether or not humans are
> around.
>
> Throughout the universe all sorts of definite things are going on right
> now, utterly unperceived by conscious intelligence. Yet they're real.
> The universe doesn't depend on human consciousness. Not one iota.
> I'm not sure what you're referring to by mesh. I picture a mesh as a
> 2D array that has been optimally triangulated. Each node connects
> to neighbors nearby, not to distant ones.
In a virtual network, nothing is distant. That is the key point.
You know from your own career that changing the paradigm (software) is
more efficient than changing the hardware.
> Each connection is the same
> capacity in terms of bandwidth. There are inherent problems with this
> if there are centralized servers everyone wants to contact -- all the
> intervening nodes get saturated just passing packets around.
No in fact trunk+branch is more resource efficient. Go study the science
on this please.
Do not tell me we have infinite resources. Yes we do, but economics still
matters, because if you violate economics, you have violated physics.
>
> If information is dumped into the mesh as a whole and spread around
> redundantly, the bandwidth is not wasted.
Exactly! That is why a virtual network is not distant! You know that
cache proxies are more numerous than servers on the internet.
You are getting it.
>
> The internet I believe today is more like the circulatory system, or
> the branches of a tree.
Exactly. Aka, "Hub and Spoke".
> Leonardo Da Vinci recognized that if you
> measure the circumference of a tree where it splits into two limbs,
> the parent limb is always the sum of the two children. This makes
> perfect sense. Ditto for the veins and arteries, they keep bifurcating
> into smaller and smaller vessels, yet the cross section of all the
> children at any node matches the cross section of the parent.
Yes you can't violate the laws of physics with your machine learning
econoimics. That has been your mistake thus far.
>
> I believe the human circulatory system takes up only 3% of the
> mass of the body -- it's incredibly efficient
YES!!!!!!!!!!!!!! EFFICIENCY!!!!!!!!!!!!!!!!
It is not critical that they be physically meshable, in fact that is not
economically efficient (refer to Coase's Theorem).
Virtual mesh (IPv4) network is more efficient, because the economics of
hub and spoke is well proven to be a lower cost structure.
Coase's Theorem is that nature will always route around any artificial
opportunity cost barrier.
IPv4 allowed for mesh networking and did not allow for the NATs we have
today. That was a corruption.
> Hope you read all my emails. Realize there are already infinite
realities out there right now. We just need to tap them. The resource
is waiting for us. We don't have to create it.
>
> We already have the pipes to it, it is called the internet.
>
> We have the computers at the end of the pipes.
>
> The problem is that those infinite realities can't be unleashed, because
the power structures are preventing those computers at the ends of the
pipes from cross connecting without going through a central server. The
server farms are the bottleneck that stifles those infinite realities
from interacting and creating the sort of automated intelligence and
results you are envisioning.
>
>
>
>> Sure, I'm curious.
>>
>>> Machine Intelligence is always bubbling in the back of my mind.
>>> > Steady progress.
>>>
>>>
>>>
>>> I know how to get what you want. And faster.
>>>
>>> Want me to explain?
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
Dynamic typing is destroying composability and evolution
![]() Shelby Mon Aug 30, 2010 5:52 pm
Shelby Mon Aug 30, 2010 5:52 pm
Type inference errors should be better programmed to illustrate the solution tree in code.
Untyped languages can not be referentially transparent, which is required for massive scale composability and parallelization (think multi-core and virtual mesh networking).
Adaption (evolution) to dynamic change requires the maximum population of mutations per generation, i.e. independent actors.
Copute the dots.
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
Free market law can defeat politics
![]() Shelby Mon Sep 13, 2010 5:10 am
Shelby Mon Sep 13, 2010 5:10 am
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
Topology of networks are driven by the constraints to the free market
![]() Shelby Wed Sep 15, 2010 11:49 am
Shelby Wed Sep 15, 2010 11:49 am
shelby wrote:It is fascinating to think of networks this way. The neurons in the brain, people in society, cities on the interstate highways, telephones in the telephone network, computers connected to the internet, hyper-links within web pages, are all interacting nodes of a massively parallel network.
Then it is interesting how the constraints effect (cause) the topology of the network, and then further contemplate how constraints can be destroyed, so as to exponentially increase the information content of society. I think such destruction mechanisms are often referred to as disruptive technology.
For example, think of how distance cost affects road networks, which is also the topology of the internet. You end up with clusters of massively parallel local connections, and then multiple large backbones connecting these.
Note how the internet has broken down the constraint of distance between people. Note how the wikipedia concept of editable web pages (which is what myspace is on a social collaboration level) has broken down the constraint of time and place to collaboration.
This theory is so powerful, it tells me precisely how to focus my work in order to become exponentially more effective on destroying the topological constraints to maximizing the information content of society (and thus on my wealth and knowledge and prosperity).
dash, I think you need to think more of your machine intelligience in terms of breaking down constraints in the potential network of real people, so that they can experience more interactions, without the material constraints.
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
Link to my economic optimization suggestion for Bittorrent.org
![]() Shelby Fri Sep 17, 2010 4:19 pm
Shelby Fri Sep 17, 2010 4:19 pm
Here is the guy "Dave" that I was discussing with:

David Harrison, Ph.D.: CTO, Co-Founder
David Harrison is Chief Technology Officer and co-founder. Prior to Flingo, he was the founder of BitTorrent.org and invented BitTorrent's Streaming protocol. David Harrison previously held a post-doctoral position in the Video and Image Processing Lab in the Electrical Engineering and Computer Sciences Department at UC Berkeley. He received a Ph.D. in Computer Science from Rensselaer Polytechnic Institute.
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
Implications of the Dunbar Number and the internet
![]() Shelby Sat Sep 18, 2010 8:57 am
Shelby Sat Sep 18, 2010 8:57 am
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
Facebook creator/CEO allegedly hacking using Facebook login data
![]() Shelby Sat Sep 18, 2010 7:09 pm
Shelby Sat Sep 18, 2010 7:09 pm
In March 2010, the website Business Insider ran a story—surprisingly under-circulated—in which sources (Business Insider got access to instant messages and emails, and conducted “more than a dozen” interviews) claim that Mark Zuckerberg, anxious about an upcoming article on the ConnectU scandal, hacked into the email accounts of two Crimson reporters, using login data he found by applying failed thefacebook.com passwords to Harvard email accounts. Later that summer, Business Insider sources show him hacking into ConnectU founders’ email addresses, forming fake Facebook profiles, and tinkering with the ConnectU site.
Business Insider also has an instant-message exchange that supposedly took place between Zuckerberg and a friend in February 2004, in which Mark boasts about all the private information he’s gleaned as Facebook czar, and calls the Harvard students that trust him “dumb fucks.”
Seems to me these illegal acts could plausibly be used by the CIA to blackmail him into letting them harvest user data:
http://www.google.com/search?q=facebook+CIA
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
Newton's Method and a much more efficient one
![]() Guest Sat Sep 18, 2010 8:46 pm
Guest Sat Sep 18, 2010 8:46 pm
Recall Newton's method for finding a square root (for example) is you start with a guess. Then you divide the original number by your guess to produce a quotient. You then average your guess with this quotient to produce a new guess. Do this repeatedly and your answer converges quickly. It turns out each step gives you one more bit of the answer, which is pretty good.
The improved method actually doubles the number of computed bits at each iteration.
Suppose you're trying to find the root of a function f(x). You pick a guess X0 and compute the value of the function. You then pick an X1 near X0 and compute the value of the function. With these 4 values you can compute the slope of the function near X0 and X1. You then compute an X2 that is your guess as to where the function will cross the X axis (Y=0). It is just an extension of the line of the slope between the two points at (X0, f(X0)) and (X1, f(X1)).
Newton's method is equivalent to finding X0 and X1 such that f(X0) and f(X1) differ in sign. So one can be certain there is a crossing of the X axis betwen them. So one computes X2 = (X0 + X1) / 2.0 and the function is evaluated. This new X2 just replaces whichever of f(X0) or f(X1) has the same sign as f(X2).
Don't know if this is relevant, I just wanted to share.
Guest- Guest
Algorithms
![]() Shelby Sat Sep 18, 2010 9:42 pm
Shelby Sat Sep 18, 2010 9:42 pm
Here are some Google Knol links:
http://knol.google.com/k/knol/Search?q=incategory:mathematics
http://knol.google.com/k/differential-binary-trees
http://knol.google.com/k/pq-trees-and-the-consecutive-ones-property
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
Re: Computers:
![]() Guest Sat Sep 18, 2010 10:02 pm
Guest Sat Sep 18, 2010 10:02 pm
Shelby wrote:Obviously the Knuth books are great.
Ah yes, obviously.
I loath Knuth and his style and his books and the ooh's and ahs that everyone pours over him. He is highly overrated. His focus is on the analysis of the efficiency of an algorithm, as opposed to the real problem which is the creative act of devising the algorithm in the first place.
He presumes a person will devote the time (and have the time to devote) for a rigourous mathematical analysis for every algorithm one considers using. What poppycock! Analysis only works for the most trivial programs and algorithms. Want to know how efficient an algorithm is? Code it up and run some timing tests. Want to know which approach is better? Implement both and compare how fast they run. No need to invest time in analyzing them. Just measure them.
My god, don't get me started. Knuth is a jackass. Ivory tower crackpot. And the fact that Bill Gates loves him lowers his reputation even more (in my eyes).
Guest- Guest
Huffman Encoding
![]() Guest Sat Sep 18, 2010 10:12 pm
Guest Sat Sep 18, 2010 10:12 pm
Ideally with Huffman encoding you have a binary tree and you decide left or right by your choice of 0 or 1 bit. Messages have a variable number of bits. The intent is for the general message to minimize the number of bits required. As an example since the letter 'e' is much more common than the letter 'q' you would want a word length for 'e' to be much shorter than the word length for 'q'.
Huffman devised a scheme that is guaranteed to create the most efficient tree. Suppose you have a list of weights for various "words" you want to encode. What you do is sort them from lowst to highest. Then you realize the two smallest ones will be siblings, and you create a node that has those as its children, and its weight is the sum of its children. The two children are now replaced in the list by the parent, and you've just gotten rid of one word you need to deal with. Do this until you're down to one word and that's the root node of the perfectly weighted tree.
Example:
3 4 5 6 12 are your weights
3 and 4 become siblings of a node with weight 7, and we resort:
5 6 7 12
5 and 6 become siblings of a node with weight 11, and we resort
7 11 12
7 and 11 become siblings of a node with weight 18, resort...
12 18
12 and 18 become siblings of a node with weight 30 and we're done.
So you're left with this encoding, 0 = left branch, 1 = right branch
1 = 12
011 = 6
010 = 5
001 = 4
000 = 3
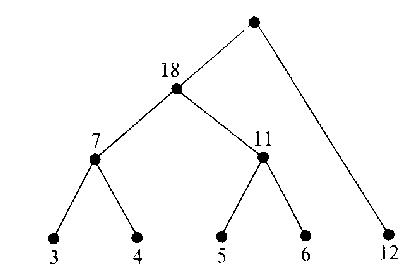
Guest- Guest
I wrote a huffman encoder for JPEG in 2008
![]() Shelby Sun Sep 19, 2010 3:11 am
Shelby Sun Sep 19, 2010 3:11 am
- Code:
/* by Shelby H. Moore III, Created: Nov. 2008, Last Updated: Nov. 2008
I make no claims nor warrents whatsoever. Please retain this header with my name in all copies.
Please kindly credit me in any derivative works.
*/
package huffman;
import Assert;
import huffman.RWbits;
// See tutorial at end of this file
class LeafCode
{
public var bitcount (default, null) : Int;
public var code (default, null) : Int;
public function new( _bitcount : Int, _code : Int )
{
bitcount = _bitcount;
code = _code;
}
}
// value of the leaf (decoded from the LeafCode)
typedef LeafValue = Value;
class Tree
{
private var leaves : Array<UInt>;
private var values : Array<Int>;
private var map : Array<LeafCode>; // map[LeafValue.value] = LeafCode, map.length == 0 if not initialized
private var invmap : Array<Array<Null<LeafValue>>>; // map[LeafCode.bitcount][LeafCode.code] = LeafValue, map.length == 0 if not initialized
private var rwbits : RWbits;
// leaves[i] = number of Huffman sub-trees of length i bits, starting from root that end at LeafCode (value not node)
// values = values of leaves in the order that corresponds to for( i in 0...leaves.length ) leaves[i];
public function new( _leaves : Array<UInt>, _values : Array<Int>, _rwbits : RWbits )
{
leaves = _leaves.copy();
values = _values.copy();
// Remove useless 0 elements at end
while( leaves[leaves.length - 1] == 0 )
leaves.pop();
map = new Array<LeafCode>();
invmap = new Array<Array<Null<LeafValue>>>();
InitMaps();
rwbits = _rwbits;
Assert.IsTrue( rwbits.rwcount >= leaves.length );
}
// Algorithm presented on page 50 of http://www.w3.org/Graphics/JPEG/itu-t81.pdf (CCITT Recommendation T.81)
/* To visualize, leaves = [0, 0, 1, 5, 1, 1, 1, 1, 1, 1] for following LeafCodes:
00
010
011
100
101
110
1110
11110
111110
1111110
11111110
111111110
*/
public function InitMaps()
{
if( map.length != 0 && invmap.length != 0 ) return; // Already done?
var code = 0;
var n = 0;
var start = 1; // skip leaves[0] because ***footnote below
var max = start + 1;
for ( i in start...leaves.length )
{
invmap[i] = new Array<Null<LeafValue>>();
Assert.IsTrue( leaves[i] <= max ); // leaves[i] can't have more values than can fit in i bits
for ( j in 0...leaves[i] )
{
var t = code /* we mask here instead of in reading and writing of bits*/& (max - 1);
map[ values[n] ] = new LeafCode( i, t );
invmap[i][t] = new LeafValue( i, values[n] );
n++;
code++;
}
code += code; // code <<= 1, code *= 2
max += max; // max <<= 1, max *= 2
}
}
// ***always node (not a leaf) at root (top) of huffman tree, see tutorial at bottom of this file
// Returned LeafCode.num_bits <= leaves.length
public inline function Encode( value : UInt )
: LeafCode
{
return map[value];
}
// Inputs bitcount significant bits (or less for last bits of encoded stream), where LeafCode is in the most significant bits
// If bitcount < leaves.length, will not match LeafCode.bitcount > bitcount
// Returns null if input matches no LeafCode
public function Decode( bits : Int, bitcount : Int )
: Null<LeafValue>
{
#if table_walk_method_to_Tree_Decode
var code = 0;
var n = 0;
//var start = 1; // skip leaves[0] because ***footnote above
var max = 2; // start + 1
var mask = bitcount; // bitcount + 1 - start
for ( i in /*start*/1...bitcount )
{
mask--;
var t = leaves[i];
if( t != 0 )
{
n += t;
code += t;
var candidate = bits >>> /*bitcount - i*/mask;
if( candidate < (code & (max - 1)) )
{
var copy = code;
for( j in 1...t+1 )
if( candidate == (--copy & (max - 1)) )
return new LeafValue( i, values[n-j] );
}
}
code += code; // code <<= 1, code *= 2
max += max; // max <<= 1, max *= 2
}
#else
//return new LeafValue( 32, bits );
//var start = 1; // skip leaves[0] because ***footnote above
var mask = bitcount; // bitcount + 1 - start
for ( i in /*start*/1...bitcount+1 )
{
mask--;
var leaf = invmap[i][bits >>> /*bitcount - i*/mask];
if( leaf != null )
return leaf;
}
#end
return null;
}
public inline function WriteEncoded( value : Int )
{
var leaf = Encode( value ); // make sure Encode() isn't called twice if Write() is inline and not optimized
Write( leaf );
}
// Input must be w.bitcount <= rwbits.rwcount, which is assured if w = Tree.Encoded()
public inline function Write( w : LeafCode )
{
rwbits.Write( w.bitcount, w.code );
}
public inline function ReadDecoded()
: Int
{
return rwbits.ReadDecoded( Decode );
}
// Same restriction on input value, as for Tree.Write()
public inline function Read( bitcount : Int )
: Int
{
return rwbits.Read( bitcount );
}
}
/* http://www.siggraph.org/education/materials/HyperGraph/video/mpeg/mpegfaq/huffman_tutorial.html
A quick tutorial on generating a huffman tree
Lets say you have a set of numbers and their frequency of use and want to create a huffman encoding for them:
FREQUENCY VALUE
--------- -----
5 1
7 2
10 3
15 4
20 5
45 6
Creating a huffman tree is simple. Sort this list by frequency and make the two-lowest elements into leaves,
creating a parent node with a frequency that is the sum of the two lower element's frequencies:
12:* <--- node
/ \
5:1 7:2 <--- leaves
The two elements are removed from the list and the new parent node, with frequency 12, is inserted into the list by frequency.
So now the list, sorted by frequency, is:
10:3
12:* <--- inserted tree node
15:4
20:5
45:6
You then repeat the loop, combining the two lowest elements. This results in:
22:*
/ \
10:3 12:*
/ \
5:1 7:2
and the list is now:
15:4
20:5
22:*
45:6
You repeat until there is only one element left in the list.
35:*
/ \
15:4 20:5
22:*
35:*
45:6
57:*
___/ \___
/ \
22:* 35:*
/ \ / \
10:3 12:* 15:4 20:5
/ \
5:1 7:2
45:6
57:*
102:*
__________________/ \__
/ \
57:* 45:6
___/ \___
/ \
22:* 35:*
/ \ / \
10:3 12:* 15:4 20:5
/ \
5:1 7:2
Now the list is just one element containing 102:*, you are done.
This element becomes the root of your binary huffman tree. To generate a huffman code you traverse the tree to the value you want,
outputing a 0 every time you take a lefthand branch, and a 1 every time you take a righthand branch.
(normally you traverse the tree backwards from the code you want and build the binary huffman encoding string backwards as well,
since the first bit must start from the top).
Example: The encoding for the value 4 (15:4) is 010. The encoding for the value 6 (45:6) is 1
Decoding a huffman encoding is just as easy : as you read bits in from your input stream you traverse the tree beginning at the root,
taking the left hand path if you read a 0 and the right hand path if you read a 1. When you hit a leaf, you have found the code.
*/
Shelby- Admin
- Posts : 3107
Join date : 2008-10-21 -
Re: Computers:
![]() Guest Sun Sep 19, 2010 3:46 am
Guest Sun Sep 19, 2010 3:46 am
Shelby wrote:I wrote a huffman encoder in HaXe (Flash, etc) for JPEG in 2008
Finally you may have actually contributed something that is useful to me. I've never heard of HaXe. I've often wanted to author flash files but want to use open source tools using traditional unix-style Makefile, text editing, etc. (as opposed to point and click user interfaces). Maybe this HaXe is the ticket.
Thanks!
Guest- Guest
Static binary trees, goertzal algorithm
![]() Guest Sun Sep 19, 2010 4:12 am
Guest Sun Sep 19, 2010 4:12 am
Shelby wrote:I wrote a huffman encoder
While we're on the subject of trees, there is a binary tree approach where the children of node N are always located at slot 2N+1 and 2N+2, and the root node is at N=0. That way if you have a static binary tree you can just hardcode it. This is used in truetype fonts (IIRC). It's an interesting puzzle how to organize your data that way if you start with an ordered list of elements.
Changing the subject...
The goertzal algorithm is very interesting. If you're interested in just a few key frequencies it is a trivial way of testing for power levels. It's used for touch tone phone recognition. I spent some time and analyzed the algorithm to figure out how it worked.
Given two samples of a signal's history differing by a constant time
delta, one can compute the next goertzel sample as follows:
a = current sample, b = previous one, c = next one
a = b = 0
LOOP:
c = 2*b*cos(theta) - a + x // x is a new sample every iteration
a=b
b=c
goto LOOP
where theta is the frequency of interest and x is a sample from
some signal source.
Guest- Guest
Page 3 of 11 • 1, 2, 3, 4 ... 9, 10, 11 ![]()